Fidelity and Biases
Dynamic Sampling allows Sentry to automatically adjust the amount of data retained based on how valuable the data is to the user. This is technically achieved by applying a sample rate to every event, which is determined by a set of rules that are evaluated for each event.
✨ Note
A sample rate is a number in the interval [0.0, 1.0] that will determine the likelihood of a transaction to be retained. For example, a sample rate of 0.5 means that the transaction will be retained on average 50% of the time.
At the core of Dynamic Sampling there is the concept of fidelity, which translates to an overall target sample rate that should be applied across all spans and transactions of an organization.
There are two available modes to govern the target sample rates for Dynamic Sampling. The definition of both the mode and the target sample rates are implemented using the organization options sentry:sampling_mode and sentry:target_sample_rate as well as the project option sentry:target_sample_rate.
- Automatic Mode dynamically manages the target sample rate for each project based on the target sample rate for the organization, prioritizing lower volume projects to increase visibility. Automatic Mode is active if the organization option
sentry:sampling_modeis set toorganization. The target sample rate for the organization is stored in the organization optionsentry:target_sample_rate, and project target sample rates are calculated based on the organization target sample rate. - Manual Mode allows the user to set static target sample rates on a per-project basis that serve as the baseline sample rate before applying the dynamic biases outlined below. Target sample rates are not adjusted by the system. Manual Mode is active if the organization option
sentry:sampling_modeis set toproject. The target sample rates for projects are stored in the project optionsentry:target_sample_rate.
All functionality defaults to Automatic Mode if the option sentry:sampling_mode is not set, and all target sample rates default to 1 if the option sentry:target_sample_rate is not set.
When the user switches between modes, target sample rates are transferred unless changed explicitly. For example, if the user switches from Automatic Mode to Manual Mode, the sample rates calculated during Automatic Mode are persisted in the project option sentry:target_sample_rate. Conversely, if the user switches from Manual Mode to Automatic Mode, the project target sample rates are recalculated based on the overall organization target sample rate.
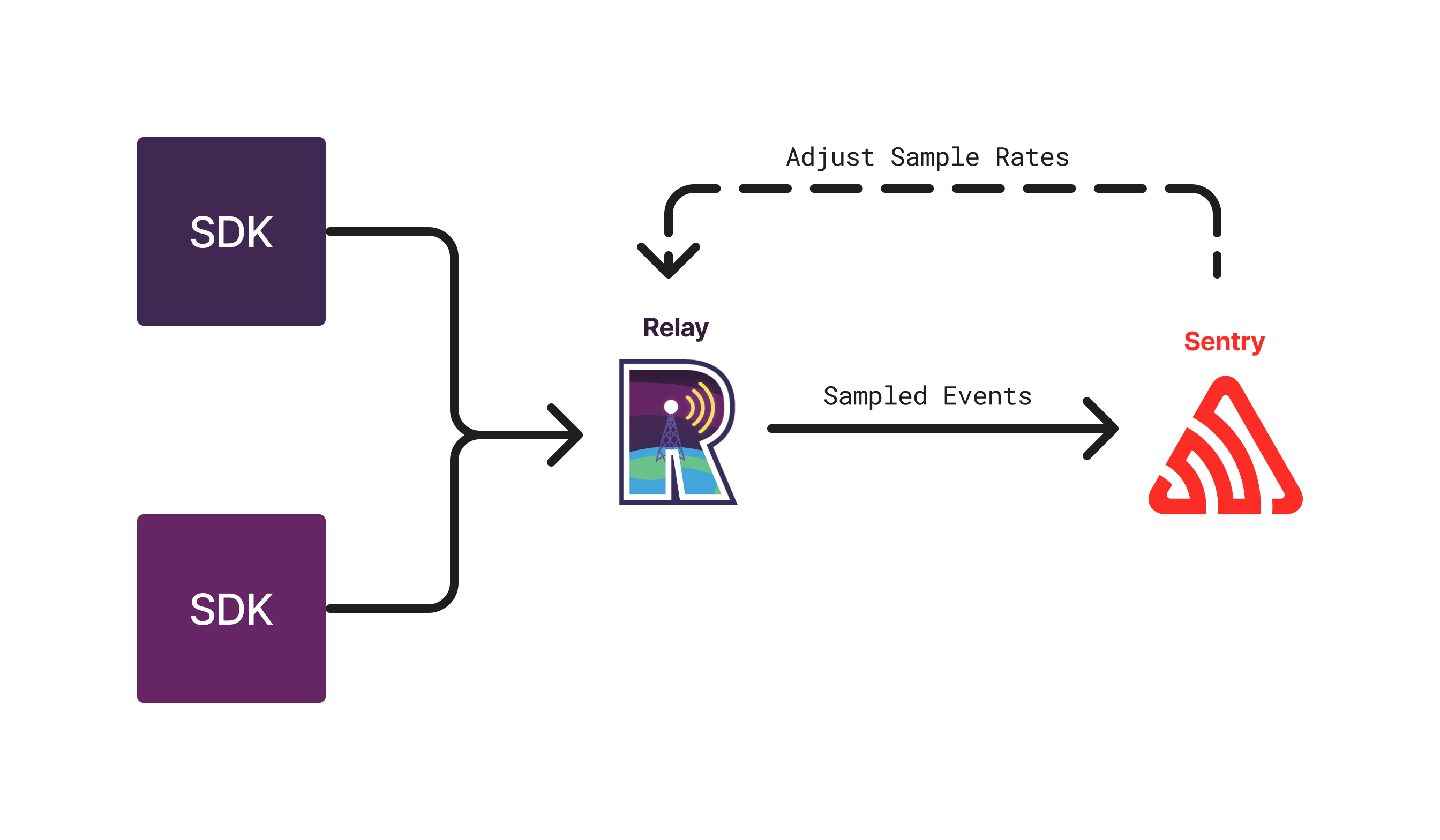
The sample rates are periodically recalibrated to ensure that the overall target sample rate is met. This recalibration is done on a project level or organization level, depending on the dynamic sampling mode. Within the target sample rate, Dynamic Sampling biases towards more meaningful data. This is achieved by constantly updating and communicating special rules to Relay, via a project configuration, which then applies targeted sampling to every event.
✨ Note
For orgs under AM2, Dynamic sampling uses a sliding window function over the incoming volume to calculate the target sample rate.
It is important to note that fidelity only determines an approximate target sample rate, so there is flexibility in creating exact sample rates. The ingestion pipeline, composed of Relay and other components, does not have the infrastructure to track volume, so it cannot create an actual weighted distribution within the target sample rate.
Instead, the Sentry backend computes a set of rules whose goal is to cooperatively achieve the target sample rate. Determining when and how to set these rules is part of the Dynamic Sampling infrastructure.
✨ Note
The effectively applied sample rate, in the end, depends on how much data matches each of the bias overrides.
Sentry supports two fundamentally different types of sampling. While this is completely opaque to the user, these rule types provide the basic building blocks for every dynamic sampling functionality and bias.
A trace is a collection of events that are related to each other. For example, a trace could contain events started from your frontend that are then generating events in your backend.
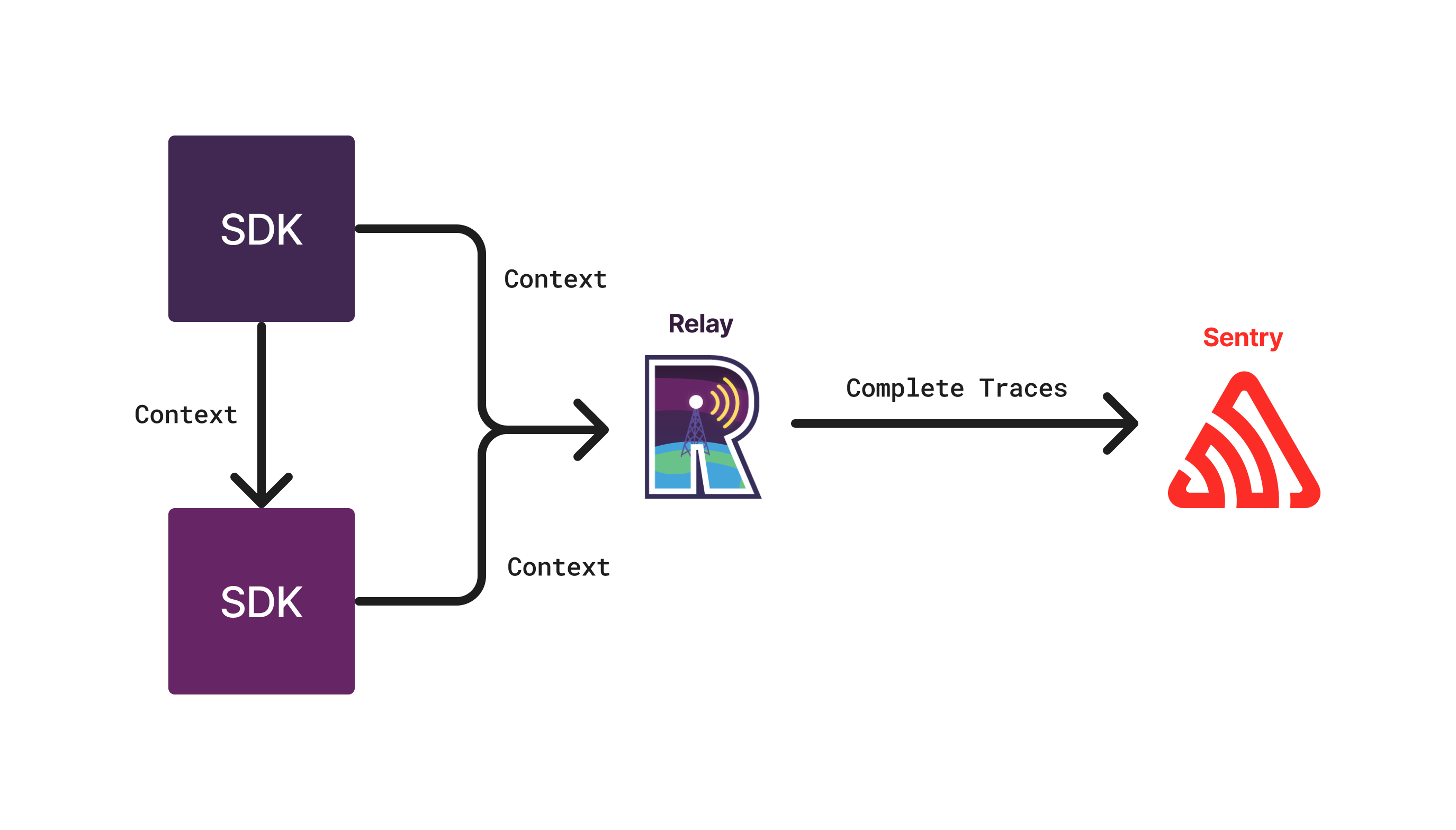
Trace sampling ensures that either all events of a trace are sampled, or none. That is, these rules always yield the same sampling decision for every event in the same trace. This requires the cooperation of SDKs and thus allows sampling only by project, release, environment, and transaction name.
To achieve trace sampling, SDKs pass all fields that can be sampled by Dynamic Sampling Context (DSC) (defined here) as they propagate traces. This ensures that every event from the same trace comes with the same DSC.
✨ Note
In order to achieve full trace sampling, the random number generator used by Relay is seeded with the trace ID inside of the DSC sent by the SDK. This ensures that traces with the same trace ID will always yield the same sampling decision.
Transaction Sampling does not guarantee complete traces and instead applies to individual transactions by looking at the incoming transaction's body. It can be used to remove unwanted transactions from traces, or to individually boost transactions at the expense of incomplete contextual traces.
A bias is a set of one or more rules that are evaluated for each event. More specifically, when we define a bias, we want to achieve a specific objective, which can be expressed as a set of rules. You learn more about rules on the architecture page here.
Sentry has already defined a set of biases that are available to all customers. These biases have different goals, but they can be combined to express more complex semantics.
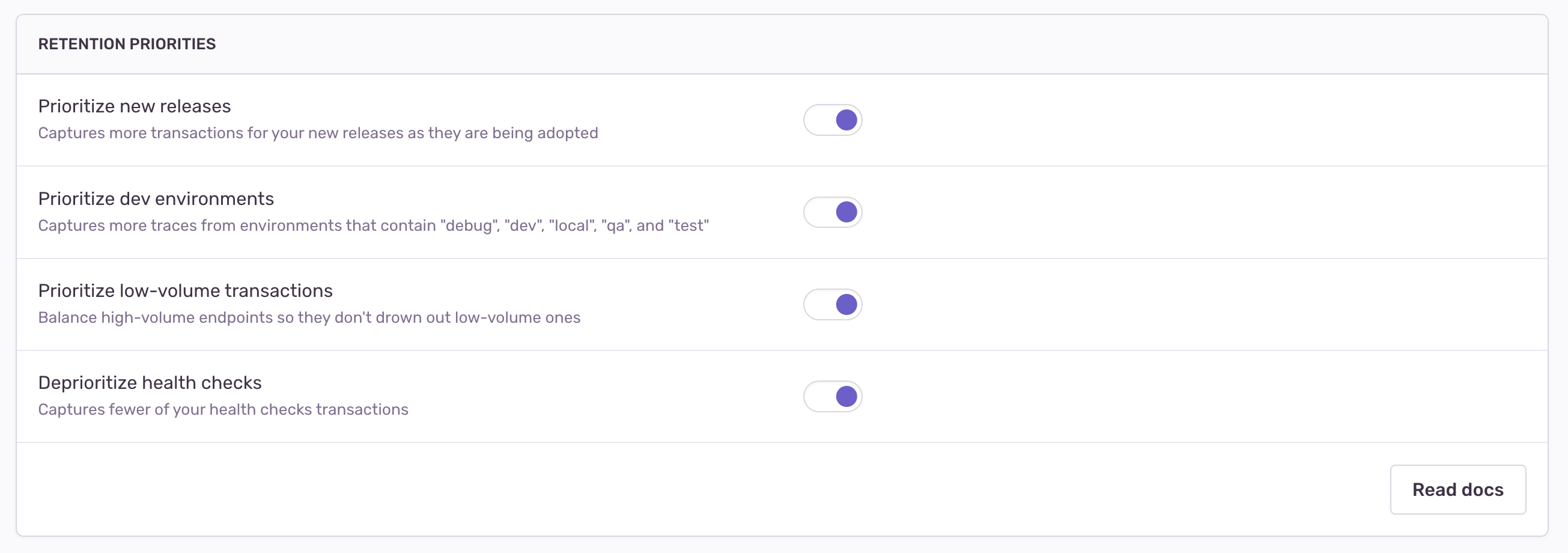
Some of the biases defined by Sentry can be enabled or disabled in the UI, more specifically under Project Settings -> Performance, while others are enabled by default and cannot be disabled.
An example of how the UI looks is shown in the following screenshot (the content of this screenshot is subject to change):
This bias is used to prioritize traces that are coming from a new release. The goal is to increase the sample rate in the time window that occurs between the creation of a release and its adoption by users. The identification of a new release is done in the event_manager defined here.
Since the adoption of a release is not constant, we created a system of decaying rules which can interpolate between two sample rates in a given time window with a given function (e.g. linear). The idea being that we want to reduce the sample rate since the amount of samples will increase as the release gets adopted by users.
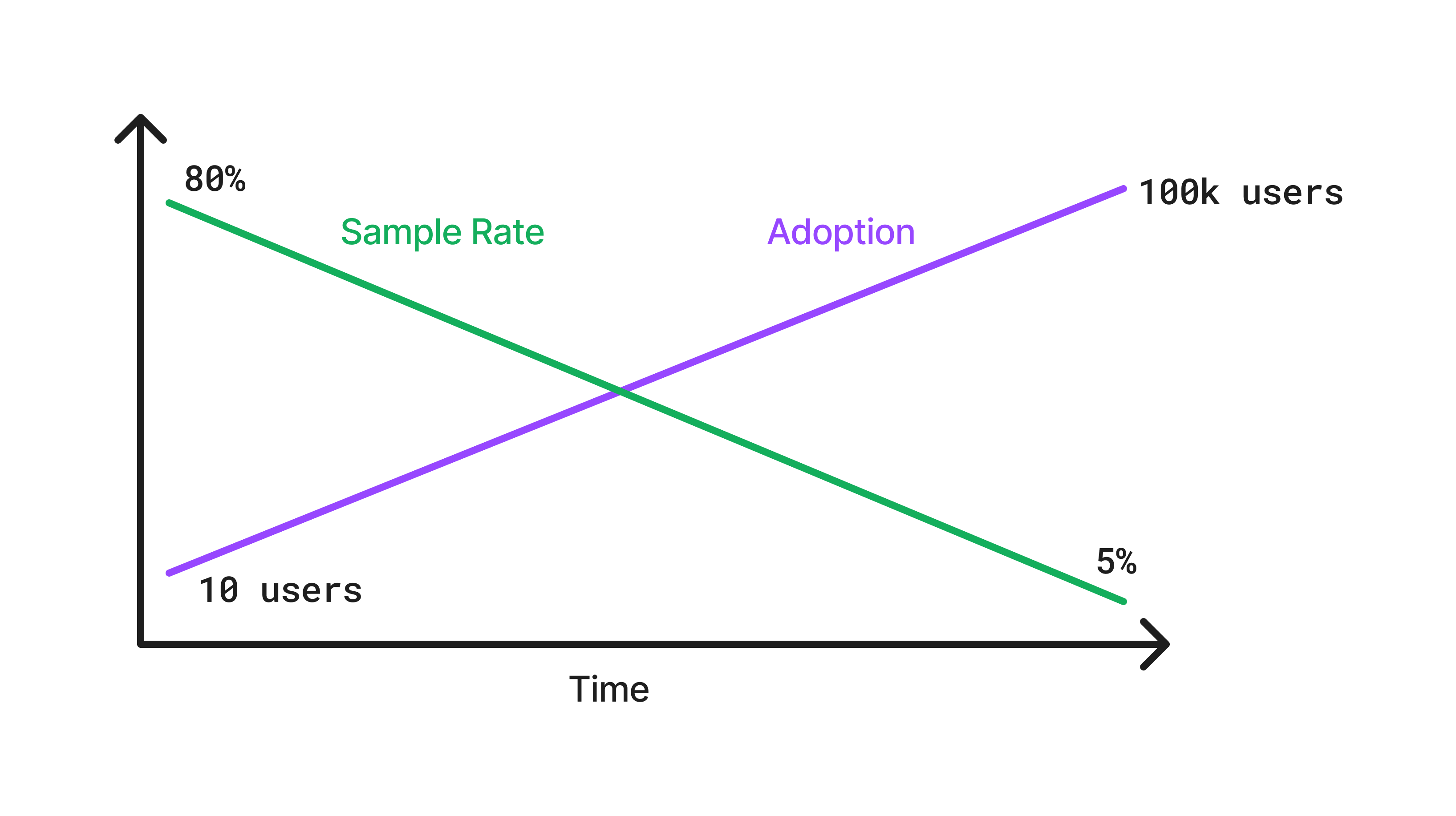
The latest release bias uses a decaying rule to interpolate between a starting sample rate and an ending sample rate over a time window that is statically defined for each platform (the list of time to adoptions is define here. For example, Android has a bigger time window than Javascript because on average Android apps take more time to get adopted by users.
This bias is used to prioritize traces coming from a development environment in order to increase the amount of data retained for such environments, since they are more likely to be useful for debugging.
To mark a trace's root transaction as belonging to a development environment, we leverage a list of known development environments, which is maintained and updated regularly by Sentry.
ENVIRONMENT_GLOBS = [
"*debug*",
"*dev*",
"*local*",
"*qa*",
"*test*",
# ...
]
The list of development environments is available here.
For prioritizing dev environments, we use a sample rate of 1.0 (100%), which results in all traces being sampled.
✨ Note
This bias is only active in Automatic Mode (and not in Manual Mode). It applies to any incoming trace and is defined on a per-project basis.
The algorithm used in this bias computes a new sample rate with the goal of prioritizing low-volume projects, which can be drowned out by high-volume projects. The mechanism used for prioritizing is similar to the low-volume transactions bias in which given the sample rate of the organization and the counts of each project, it computes a new sample rate for each project, assuming an ideal distribution of the counts. The sample rate of the boost low volume projects bias is computed using an algorithm that leverages a dynamic sample rate obtained by measuring the incoming volume of transactions in a sliding time window, known as the target fidelity rate. This rate is obtained by calling, at fixed intervals, the get_sampling_tier_for_volume function (defined here).
This bias is used to prioritize low-volume transactions that can be drowned out by high-volume transactions. The goal is to rebalance sample rates of the individual transactions so that low-volume transactions are more likely to have representative samples. The bias is of type trace, which means that the transaction considered for rebalancing will be the root transaction of the trace.
Prioritization of low volume transactions works slightly differently depending on the dynamic sampling mode:
- In Automatic Mode (
sentry:sampling_mode==organization), the output of the boost_low_volume_projects task is used as the base sample rate for the balancing algorithm. - In Manual Mode (
sentry:sampling_mode==project), the project target sample rate is used as the base sample rate for the balancing algorithm.
In order to rebalance transactions, the system retrieves the counts of the transactions for each project and calculates a new sample rate for each transaction.
✨ Note
The algorithms for boosting low volume events are run periodically (with cron jobs) with a sliding window to account for changes in the incoming volume.
This bias is used to de-prioritize transactions that are classified as health checks. The goal is to reduce the amount of data retained for health checks, since they are not very useful for debugging.
In order to mark a transaction as a health check, we leverage a list of known health check endpoints, which is maintained by Sentry and updated regularly.
HEALTH_CHECK_GLOBS = [
"*healthcheck*",
"*healthy*",
"*live*",
"*ready*",
"*heartbeat*",
"*/health",
"*/healthz",
# ...
]
The list of health check endpoints is available here.
For deprioritizing health checks, we compute a new sample rate by dividing the base sample rate of the project by a factor, which is defined here.
If you want to learn more about the architecture behind Dynamic Sampling, continue to the next page.
Our documentation is open source and available on GitHub. Your contributions are welcome, whether fixing a typo (drat!) or suggesting an update ("yeah, this would be better").